DebateExplorer: Wenn Maschine und Journalist zusammenarbeiten
200 000 Seiten Text kann kein Journalist mal eben für eine Recherche lesen und einordnen. Aber ein Computer kann das sehr wohl. Wenn er weiß, wonach er suchen soll — und da kommt wieder der Journalist ins Spiel. Der DebateExplorer zeigt, wie Mensch und Maschine zusammen Lobbyismus auf die Spur kommen können.
Beispielthema Datenschutz: Welche Partei setzt sich in der Politik für welche Position ein? Artikel und Berichte dazu bilden immer nur den groben Ist-Zustand ab. Spannender wäre aus journalistischer Sicht einen Schritt zurückzugehen, um herauszufinden, wann in der politischen Debatte eine bestimmte Partei angefangen hat, sich positiv oder negativ über Datenschutz zu äußern.
"In Gesprächen wiesen Kollegen immer wieder darauf hin, dass sich hier der Einfluss der Lobbyisten zeigt", sagt Journalistin Eva Wolfangel. Politiker wie Jan Philipp Albrecht von den Grünen haben das bestätigt; er sei noch nie so stark von Lobbyisten angegangen worden wie beim Thema Datenschutz.
Aber wie kann man den Einfluss von Lobbyisten auf die Position eines Politikers nachweisen? Mit dieser Frage im Kopf besuchte Wolfangel einen Vortrag des Computerlinguisten Jonas Kuhn, in dem er erklärte, wie die automatisierte Übersetzung von großen Textmengen funktioniert. "Und ich habe mir gedacht: Eine solche Technik, die große Mengen an Sprachdaten analysieren kann, müsste man genauso auf die Sitzungsprotokolle der Politiker anwenden können."
Gemeinsam formulierten die Journalistin Eva Wolfangel und die Wissenschaftler Jonas Kuhn und André Blessing ihr Ziel: 200.000 Seiten Text aus Bundestagsdebatten nach Personen, Themen und vor allem Meinungen durchsuchbar zu machen. Und zwar so, dass sich zeigen lässt, wann sich ein Politiker wie häufig zu einem bestimmten Thema äußert, wie etwa zum Datenschutz — und wie sich seine Einstellung zu diesem Thema über die Zeit eventuell verändert.
Von der Idee zum Prototyp — über viele Hürden
"Die einzelnen Komponenten des DebateExplorers nutzen wir bereits in anderen wissenschaftlichen Zusammenhängen", sagt Computerlinguist Kuhn. "Die große Herausforderung war für uns, die Elemente so in eine Architektur zusammenzubauen, dass daraus ein interaktives Tool wird und die Maschine so zu trainieren, dass die Ergebnisse möglichst akkurat sind: Wie kann man das 'Rauschen' in den Ergebnissen so weit reduzieren, dass die Journalisten in vertretbarer Zeit 'Signale' finden?"
Wenn man bei Google den Begriff "Datenschutz" eintippt, durchforstet der Algorithmus zahllose von Webseiten und Dokumenten und findet 219 Millionen Treffer. Was die Suchmaschine jedoch nicht kann, ist einzuschätzen, ob das Suchergebnis dem Thema positiv oder negativ gegenüber eingestellt ist.
Dabei wäre diese qualitative Aussage technisch möglich: Computerlinguisten können Algorithmen trainieren zu erkennen, ob eine Bewertung positiv oder negativ ist. Ein Trainingsbeispiel sind etwa Buchkritiken von Nutzern auf Amazon: Der Algorithmus schaut auf das Ergebnis - gute oder schlechte Bewertung - und lernt, welche Worte mit einer guten oder schlechten Bewertung assoziiert sind. Ausgehend von diesem Grundwissen über die Verwendung von Wörtern können dann auch neue Texte maschinell eingeschätzt werden.
"Es gibt inzwischen keinen großen Konzern mehr, der nicht Text Mining und Sentiment Analyse nutzt. Damit lassen sich soziale Medien durchforsten, um herauszufinden, welche Meinungen Nutzer über die Produkte des Unternehmens haben — und um bei Bedarf schnell auf Kritik reagieren zu können", sagt Kuhn.
Der Algorithmus lernt: Ist das Zustimmung oder Ablehnung?
Auch der DebateExplorer wurde zunächst mit den Amazon-Bewertungen trainiert. Und musste lernen, dass bestimmte Wörter unterschiedliche, bisweilen sogar gegensätzliche Bedeutung haben können, je nach Sinnzusammenhang: "Der Algorithmus hat zum Beispiel das Wort 'warm' positiv annotiert. Dabei kann es aber auch etwas Negatives sein, wenn es sich zum Beispiel auf Bier bezieht", so Wolfangel.
Politische Debatten sind natürlich umfassender als Amazon-Bewertungen, was das Projekt nicht einfacher gemacht hat: "Wir haben nicht damit gerechnet, wie schwierig es sein würde, die Position eines Politikers anhand von Redetexten von einem Computer bewerten zu lassen: Denn bevor er seinen Standpunkt äußert, führt er zuerst die ganzen Argumente der Gegenseite auf", erklärt Kuhn.
Für den Algorithmus erschließt sich so nicht, welche Meinung der Politiker hat, da den Argumenten der Gegenseite mehr Platz im Beitrag eingeräumt wird, als der eigenen, entgegengesetzten Position. "Wir mussten dem Computer also beibringen, dass wahrscheinlich das, was am Ende der Rede kommt, von größerer Bedeutung ist als das, was am Anfang steht", so Kuhn.
Komplexe Rhetorik trifft auf einfache Logik
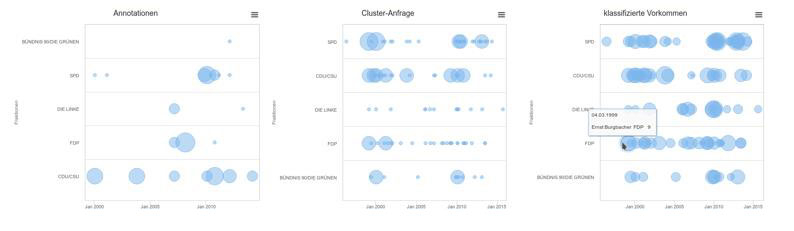
"Zu Beginn des Projektes haben wir gehofft, dass man die Polarität eines Politikers anhand seiner Wortwahl feststellen kann. Das ist uns leider nicht gelungen", sagt Kuhn. "Derzeit visualisiert unser Tool im zeitlichen Verlauf, wie häufig ein bestimmter Begriff in einer bestimmten Fraktion genannt wird. Es ist also mehr ein Fingerzeig für Journalisten, in welchem Bereich es sich lohnen könnte, weiter zu suchen."
Wenn der DebateExplorer online ist, liefert er nach Eingabe des Suchbegriffs eine Visualisierung: Jeder Bundestagsfraktion wird dabei eine Linie zugeordnet, auf deren Verlauf Kreise abgebildet sind. Diese geben an wie oft das gesuchte Thema im Zusammenhang mit dieser Fraktion in Sitzungsprotokollen erwähnt wurde. Über einen Klick gelangt man direkt zu den Originaldokumenten.

Damit die Maschine zu diesem Ergebnis kommt, müssen Journalist und künstliche Intelligenz zusammenarbeiten. Denn der Algorithmus des DebateExplorer arbeitet nicht mit einem festen Katalog von "positiven" oder "negativen" Worten. Das heißt im Umkehrschluss: Für jedes neue Thema, nach dem ein Journalist die Protokolle der Bundestagsdebatten durchsuchen will, muss er diese grundlegende Sortierung vornehmen. "Man gibt der Maschine einige markierte Textbeispiele, von mir als Journalistin unterteilt in 'dafür' und 'dagegen'. Basierend auf diesen Beispielen leitet sich der Algorithmus daraus selbst Muster ab, um zu entscheiden, wie ein Text einzuordnen ist", erklärt Wolfangel den Prozess.
Lernprozess: Im Maschinenraum des Algorithmus
Für diese Klassifizierung nutzt der Algorithmus in seinem Lernprozess sogenannte Latent-Topic-Modelle. Sie erzeugen Wortwolken aus Texten: Welche Begriffe kommen häufiger vor, welche weniger häufig? In der Nähe bzw. im Zusammenhang mit welchen anderen Wörtern kommt ein bestimmtes Wort vor? Diese Wolken werden dann jedoch nicht direkt durchsucht, sondern als Blaupause zum Vergleich herangezogen: Weicht eine bestimmte Rede erkennbar vom normalen Muster ab?
Dann startet der Trainingsprozess der künstlichen Intelligenz: Man gibt ihr große Textmengen, die sie klassifizieren soll: Welche Texte entsprechen dem gesuchten Muster und welche nicht? Anhand der Abweichung versucht der Algorithmus dann Positionen zu erkennen: Handelt es sich um eine Zustimmung oder Ablehnung des Themas? Grenzfälle werden von Hand in die richtige Kategorie einsortiert. So wird die Maschine immer effektiver darin, eine Position einzuordnen. "Wir durchlaufen in der Regel zwei bis drei Trainingsschleifen, bis wir an einen Punkt kommen, an dem die Maschine zufriedenstellende Ergebnisse liefert", so Kuhn.
Die Grenzen der künstlichen Intelligenz
In den USA gibt es vergleichbare Versuche, Sentiment-Analyse auf große Textmengen anzuwenden — wobei diese vom Umfang eher kleiner sind als der Korpus des DebateExplorers. Auch in einem Projekt der Washington Post zeigte sich, dass vom Algorithmus positiv annotierte Worte in dem speziellen Kontext tatsächlich nicht positiv waren. Obwohl es im Englisch-sprachigen Raum bereits durchaus mehrere Initiativen gibt, lassen sich bisherige Erkenntnisse nicht 1:1 übertragen — schließlich hat jede Sprache eine eigene Grammatik, nach der Sätze aufgebaut werden, was von einem Algorithmus genauso erlernt werden muss, wie von einem Menschen. Das wiederum bietet Ansätze für weitere Forschung: So untersuchen etwa norwegische Computerlinguisten, ob sich eine automatisierte Systematik entwickeln lässt, die allen "kleineren" Sprachen zugute kommen würde.
Unabhängig von sprachlichen Spitzfindigkeiten hat das Potenzial der künstlichen Intelligenz auch Grenzen. So würde sich Kuhn niemals ausschließlich nur auf das Ergebnis des Algorithmus verlassen: "Wir würden unsere Hand nie ins Feuer dafür legen, dass ein Treffer nicht doch ein Artefakt ist. Deswegen liefert unser Tool den direkten Link zur Originalquelle. Wir weisen Nutzer darauf hin, diese auf jeden Fall zu konsultieren und sich nicht auf die Scheinobjektivität der Visualisierung zu verlassen."
Nach neun Monaten Teamwork mit der künstlichen Intelligenz ist Eva Wolfangel den technischen Möglichkeiten aufgeschlossen, sieht darin aber keine Konkurrenz für Journalisten: "Ich glaube nicht, dass Roboter den Job von uns Journalisten übernehmen können. Durch das Projekt habe ich festgestellt, wie aufwändig es ist, dafür zu sorgen, dass Algorithmen so etwas Komplexes wie Sprache verstehen. Ich kann mir vorstellen, dass Roboter Wetterberichte oder Sportberichte verfassen,wie es ja auch schon passiert, weil es dabei um ein recht mechanisches Abbilden von Fakten geht. Aber Journalismus bedeutet ja auch sprachliche Kreativität, erst daraus entsteht Qualität. Und das ist etwas, das auch eine künstliche Intelligenz nicht kann. Aber es ist ja gut, wenn sie uns die rein faktische Ergebnis-Berichterstattung abnehmen können, damit wir mehr Zeit für die kreativen Inhalte haben."
Gianna Grün
Projektinformationen DebateExplorer
Hauptantragsteller:
Jonas Kuhn, Universität Stuttgart
Eva Wolfangel, Freie Wissenschaftsjournalistin
Projektwebsite DebateExplorer: https://www.debateexplorer.de
Publikationen
Dieu-Thu Le, Ngoc Thang Vu, André Blessing (2016). Towards a text analysis system for political debates. In: Proceedings of the 10th SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (LaTeCH), Berlin, August 11, Association for Computational Linguistics, pp. 134-139.
Jonas Kuhn, André Blessing, Markus John, Steffen Koch, Thomas Ertl (eingereicht). Reflected text analytics through interactive visualization. In. Miriam Butt, Annette Hautli-Janisz and Verena Lyding (eds.): Linguistic Visualizations, Stanford, CA: CSLI Publications.
Kuhn, Jonas und André Blessing (erscheint). Die Exploration biographischer Textsammlungen mit computerlinguistischen Werkzeugen – methodische Überlegungen zur Übertragung komplexer Analyseketten in den Digital Humanities. In: C. Gruber et al. (eds.) Europa baut auf Biographien, Österreichische Akademie der Wissenschaften.